Random Forest Classification for LiDAR Data
A feature-engineered classification workflow for point clouds, built for speed, interpretability, and practical benchmarking.
This project applies random forest classification to airborne or mobile LiDAR point clouds. While deep learning receives most of the attention in 3D ML, well-engineered classical models remain highly competitive in many practical settings, especially when feature quality, training cost, and interpretability matter.
The core of the workflow is feature engineering. For each point, I computed geometric and volumetric descriptors across multiple neighborhood radii, using K-nearest-neighbor relationships to capture local structure. To keep the pipeline efficient on large point clouds, I accelerated key preprocessing steps in Cython rather than relying only on pure Python.
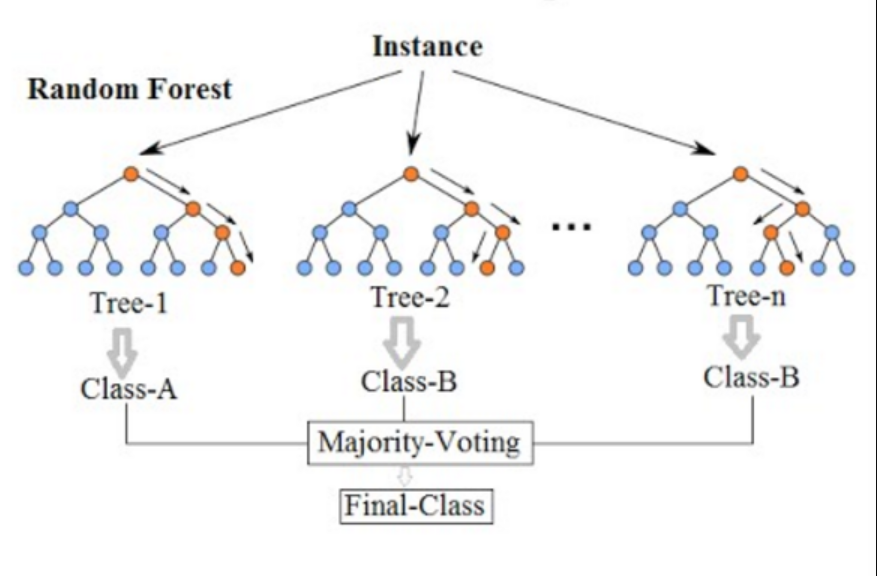
The resulting features were then used in a scikit-learn random forest classifier for semantic labeling. In practice, this kind of workflow is useful both as a production baseline and as a benchmark against more complex 3D models such as PointNet++ and PointCONV. It provides a strong reference point for understanding what additional model complexity actually buys you.
This page summarizes the technical approach at a high level. Some code from company work is not public, but the workflow reflects real production and benchmarking experience in LiDAR classification.
